Journal Name: Journal of Multidisciplinary Research and Reviews
Article Type: Research
Received date: 20 November, 2019
Accepted date: 27 December, 2019
Published date: 03 January, 2020
Citation: Ramakrishna S, Aiyer K (2019) Speeding up the Karatsuba Algorithm. J Multidis Res Rev Vol: 2, Issu: 1 (01-03).
Copyright: © 2019 Ramakrishna S. This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Abstract
The Karatsuba method was the first published attempt to speed up the multiplication of two numbers [1]. It is well-known to be of complexity . There are currently, improved mathematical algorithms that surpass this algorithm in complexity [2-7].
While it does not seem possible to improve upon the basic mechanism of the Karatsuba technique and we demonstrate why it is the most efficient of its type, it is possible that one can improve its implementation for particular decile ranges of numbers. This article presents an approach to speed up the implementation of the Karatsuba technique, utilizing extra memory to supplement the original method. While the method is conceptually similar to the “Method of Four Russians” technique used to speed up Matrix Multiplications, it applies the concept in a different area.
The Karatsuba algorithm [1,2], an technique to multiply two n-digit numbers, has been surpassed by newer techniques that are O(n×log n×log log n) [3-7] and O(n×log n) [8] respectively. However, the simplicity of the algorithm allows improvements that are easily implemented and can be reduced to fewer multiplications, supplemented by look-ups.
Keywords
Karatsuba algorithm, Method of Four Russians, Matrix multiplications, Complexity.
Abstract
The Karatsuba method was the first published attempt to speed up the multiplication of two numbers [1]. It is well-known to be of complexity . There are currently, improved mathematical algorithms that surpass this algorithm in complexity [2-7].
While it does not seem possible to improve upon the basic mechanism of the Karatsuba technique and we demonstrate why it is the most efficient of its type, it is possible that one can improve its implementation for particular decile ranges of numbers. This article presents an approach to speed up the implementation of the Karatsuba technique, utilizing extra memory to supplement the original method. While the method is conceptually similar to the “Method of Four Russians” technique used to speed up Matrix Multiplications, it applies the concept in a different area.
The Karatsuba algorithm [1,2], an technique to multiply two n-digit numbers, has been surpassed by newer techniques that are O(n×log n×log log n) [3-7] and O(n×log n) [8] respectively. However, the simplicity of the algorithm allows improvements that are easily implemented and can be reduced to fewer multiplications, supplemented by look-ups.
Keywords
Karatsuba algorithm, Method of Four Russians, Matrix multiplications, Complexity.
The Karatsuba Algorithm
For simplicity, consider multiplying two n-digit numbers x and y, written as
where for simplicity, we use , and work in base-10. The product can be simplified to
so that the product of the n-digit numbers can be reduced to the multiplication of three independent m-digit (and occasionally m+1-digit) numbers, instead of four m-digit numbers. Note that multiplications by 10 are ignored in the complexity calculations, since they can be reduced to decimal point shifts before additions. Also, as a general principle, the complexity calculation ignores the number of additions, since they are sub-dominant in complexity. The order of magnitude (“complexity”) of the number of separate multiplications to multiply these two numbers can be reduced to the relation
The Karatsuba technique is sometimes referred to as the “divide-by-two-and-conquer” method.
An alternative approach to computing the complexity above is as follows. At every step, the starting number (initially n = 2s digits long) is split into two numbers with half the number of digits. After s steps, it is easy to see that 3s multiplications of single-digit numbers need to be performed. This number, the number of multiplications required, can be written as ; hence the above complexity result. This calculation is exact (as explained above) for a number with a power of 2 as the number of digits.
The Improved Version
We generalize the Karatsuba divide-by-two-and-conquer algorithm as follows and write (in base-B)
As can be quickly checked, each of the numbers x0, ..., xN , y0, ..., yN are m-digits long and (N + 1)m = n where n is the total number of digits in x and y.
The number of multiplications required to multiply x and y, i.e., the order of complexity, is individual products of m-digit (and occasionally m+1-digit) numbers. For instance, if N = 1, as in the usual Karatsuba technique, ℳ = 2 + 1 = 3 which is what we use in the orderof- magnitude estimate in Equation (3).
In the Karatsuba technique, the m(= 2) digit numbers are further multiplied by the same technique, carrying on recursively till we are reduced to single-digit multiplications. That leads to the recursive complexity calculation noted in Equation (3).
However, note that if we simply pre-computed the individual m-digit multiplications and looked up the individual multiplications, we end up with essentially lookups rather than actual multiplications. Indeed, lookups take, on average, 1/5 the time taken for single- digit multiplication (and then we have to multiply by the number of operations L required to perform the lookup), hence the complexity when lookups are added are in comparison with the Karatsuba method. As we will show below, L ∼ 6m, so that the total complexity of the algorithm is . If m were chosen to be a fraction of n, i.e., , the complexity is ∼ (N + 1)n. When compared to the Karatsuba technique, this is much quicker than n1.58. This is the main result of this short note.
The lookups of m-digit multiplications need to be performed against a table of size Bm × Bm. This lookup, as can be verified by standard binary-search techniques, is (for B = 10) of complexity . There are some additional additions and subtractions, which add additional (though sub-dominant) complexity as can be easily checked and are detailed in the below example.
Analyzing this further, we could choose to mix and match in two different ways, i.e.,
- 1. We could apply k Karatsuba-style divide-by-two-andconquer steps, then apply the lookup method to look-up 3k pre-calculated products of digits or
- 2. We could use the (N + 1) = 2k-block technique (break-up into m digit blocks) with , we’d have to look-up 2k + C(2k, 2) products.
It is clear that 3k < 2k + C (2k, 2), so the divide-by-two-andconquer strategy yields fewer lookups - it is the quickest way to speed up the calculation. A graph of the reduced com- plexity (essentially ) achieved this way is plotted in Figure 1 - clearly, cutting the recursion off early is advantageous.
Figure 1
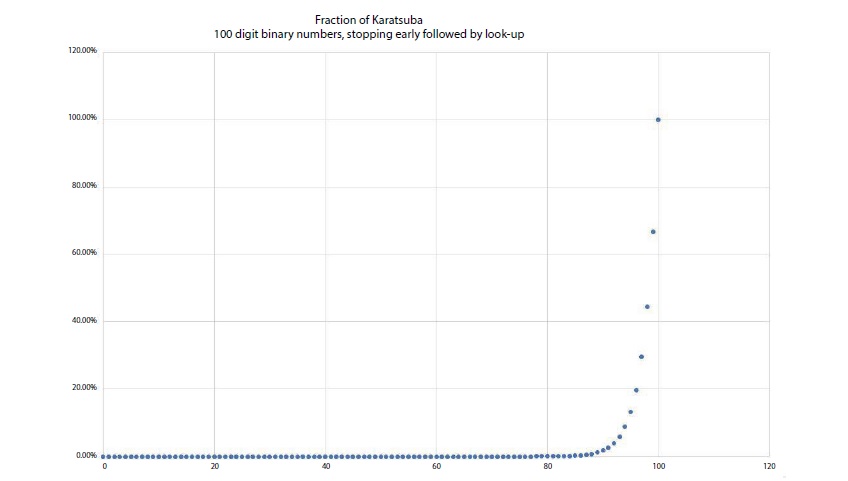
Figure 1: Plot of the Efficiency of cutting off Karatsuba early.
A little reflection will show why divide-and-conquer by 2 for k times followed by lookup is the most efficient way to carry out the above procedure, in fact it is illustrative for it demonstrates why the Karatsuba technique is the most efficient of the divide-and-conquer techniques. Each time we divide an n-digit number into N + 1 blocks of m-digits, we have to (recursively) perform (N + 1) + C(N + 1, 2) multiplications. After k such recursions, we are left with (N + 1)k blocks of n digits each and have to perform ((N + 1) + C(N + 1, 2))k multiplications. At this point, if we look up pre-computed products of numbers of this type, that is a complexity factor of . The total number of operations is
which is smallest for smallest N , i.e., N = 1. The complexity then matches exactly the complexity of the Karatsuba algorithm.
Numerical example
The above arithmetic is demonstrated in the case below for N = 4, where we have used n = 5m,
which leads to the product
As can be observed, this expression has 5 + C(5, 2) = 15 independent products that can be pre-computed, i.e.., the 5 simple products x0y0, x1y1, x2y2, x3y3, x4y4 and the 10 combination products (x0 +x1)(y0 +y1), (x0 +x2)(y0 +y2), (x0 +x3) (y0 +y3), (x0 +x4)(y0 +y4), (x1 +x2)(y1 + y2), (x1 +x3)(y1 +y3), (x1 +x4)(y1 +y4), (x2 +x3)(y2 +y3), (x2 +x4)(y2 +y4), (x3 +x4)(y3 +y4).
If these products are found in a pre-computed table of m and (m + 1)-digit numbers, we would not need any multiplications at all, just 15 lookups, for any m, with n = 5m.
We would need to perform additions and subtractions, of course and there are 34 of them in the above example - this number of elementary operations depends, however, only upon .
Memory Requirements
Typical RSA encryption algorithms use ∼ 1000-digit base-10 composite numbers that are the product of five-hundred-digit primes. If one were to attack the problem by pre-computing keys, i.e., pre-multiplying pairs of five-hundred-digit primes (n = 500 ∼ 29) and storing the results of multiplying all possible 6-digit numbers (m = 6 ∼ 23), one has a complexity , which is worse than the new ∼ n log2n ∼ 4500 complexity [8], albeit the fact that the newer approach also has multipliers, which we have not accounted for. If we use the hybrid method (Karatsuba followed by look-up of 6-digit products), the complexity is ∼ 36 × 6 ∼ 4200, which is arguably much better (no pre-factors missing) than even the n log2n algorithms. We would need to store ∼ 1012 twelve-digit numbers, roughly 20 TB of memory, which is a reasonable size.
Conclusion
This paper presents a rapid pre-computed approach to speeding up multiplications. Though one needs to pre-compute and store all possible m-digit multiplications, one can compute the products of two integers with number of digits equal to any integer times m in time proportional to the number of digits (times the afore-mentioned integer). Memory is cheaper than CPU-speed, so this is a method that can be exploited in other (for instance signal-processing) situations to speed up intensive calculations too.
Useful conversations are acknowledged with Dr. B. Kumar. As this paper was being prepared, an article about using pre-stored calculations was released, where the Eratosthenes sieve was sped up in calculation complexity [9,10].

View pdf
Download pdf
There are no references
